Database Scaling Made Simple: Understanding Read Replication and Data Sharding
As applications grow, so does the amount of data they need to handle. What works perfectly for a small startup may start slowing down when thousands or millions of users begin using the application.
This is where database scaling comes in.
In this blog, we'll explore two common database scaling techniques:
Multi Read Replication
Data Sharding
We'll keep things simple and avoid complex database jargon.
Why Do We Need Database Scaling?
Imagine you own a small restaurant.
Initially, one chef can handle all customer orders. But as your restaurant becomes popular, customers start waiting longer because one chef can't keep up.
You have two options:
Hire more chefs to help with cooking.
Split responsibilities among multiple kitchens.
Database scaling works in a similar way.
As traffic increases:
More users read data.
More users write data.
Database response times become slower.
The server becomes overloaded.
To solve this problem, we scale the database.
What is Database Scaling?
Database scaling means increasing the database's ability to handle more traffic, more users, and more data without becoming slow or unavailable.
There are two common approaches:
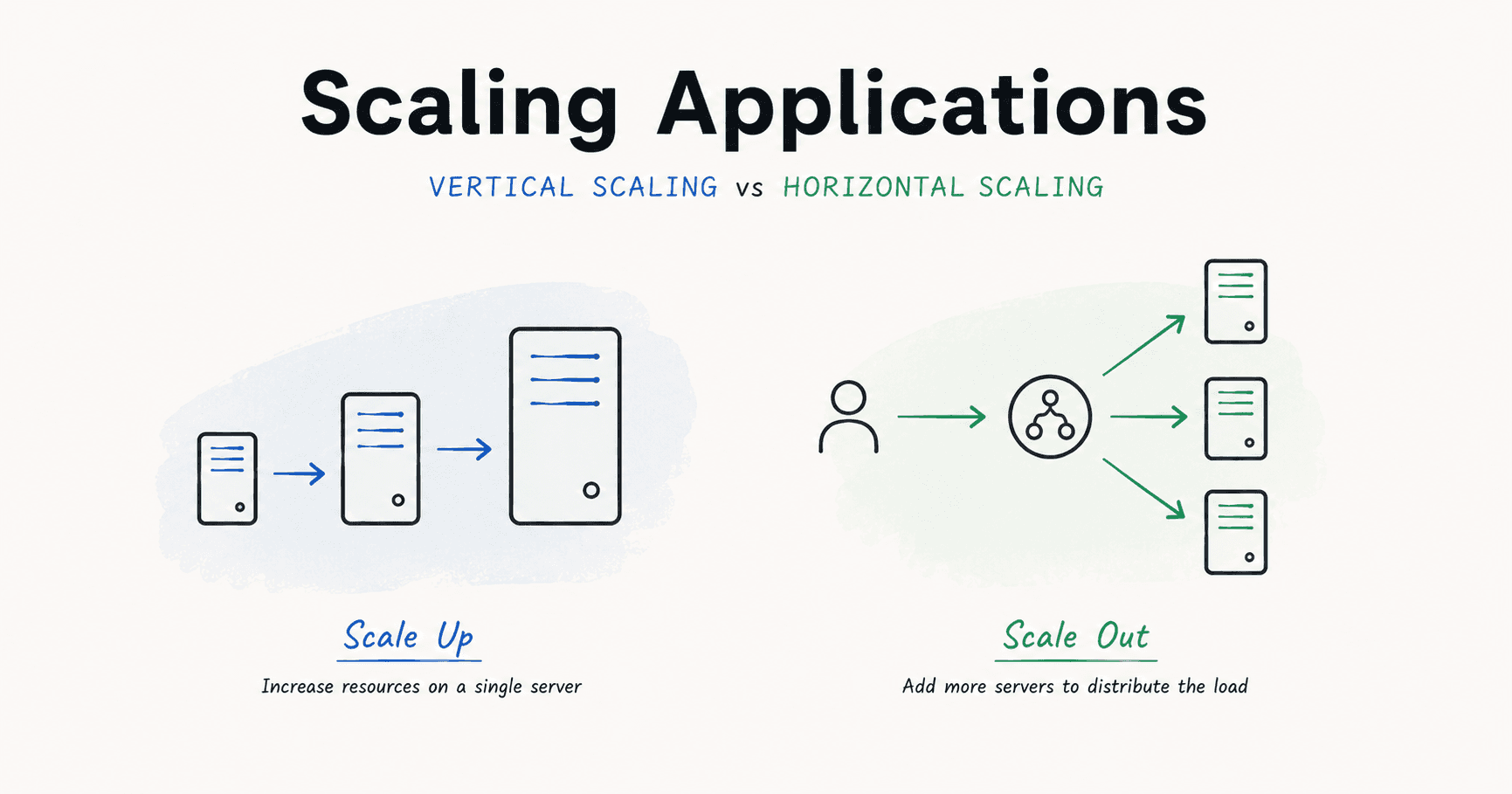
Vertical Scaling
Upgrade the existing server:
More CPU
More Memory (RAM)
Faster Storage
Example:
Moving from an 8 GB RAM server to a 64 GB RAM server.
Pros
Easy to implement
No application changes
Cons
Expensive
Has physical limits
Horizontal Scaling
Instead of making one server bigger, add more servers.
Example:
1 Database Server → 5 Database Servers
This approach is more scalable and is commonly used by large applications.
Multi Read Replication
One of the biggest loads on a database comes from read operations.
Examples:
Viewing profiles
Loading product pages
Reading posts
Searching data
In many applications, reads are much more frequent than writes.
A common pattern is:
90% Reads
10% Writes
So why should one database handle everything?
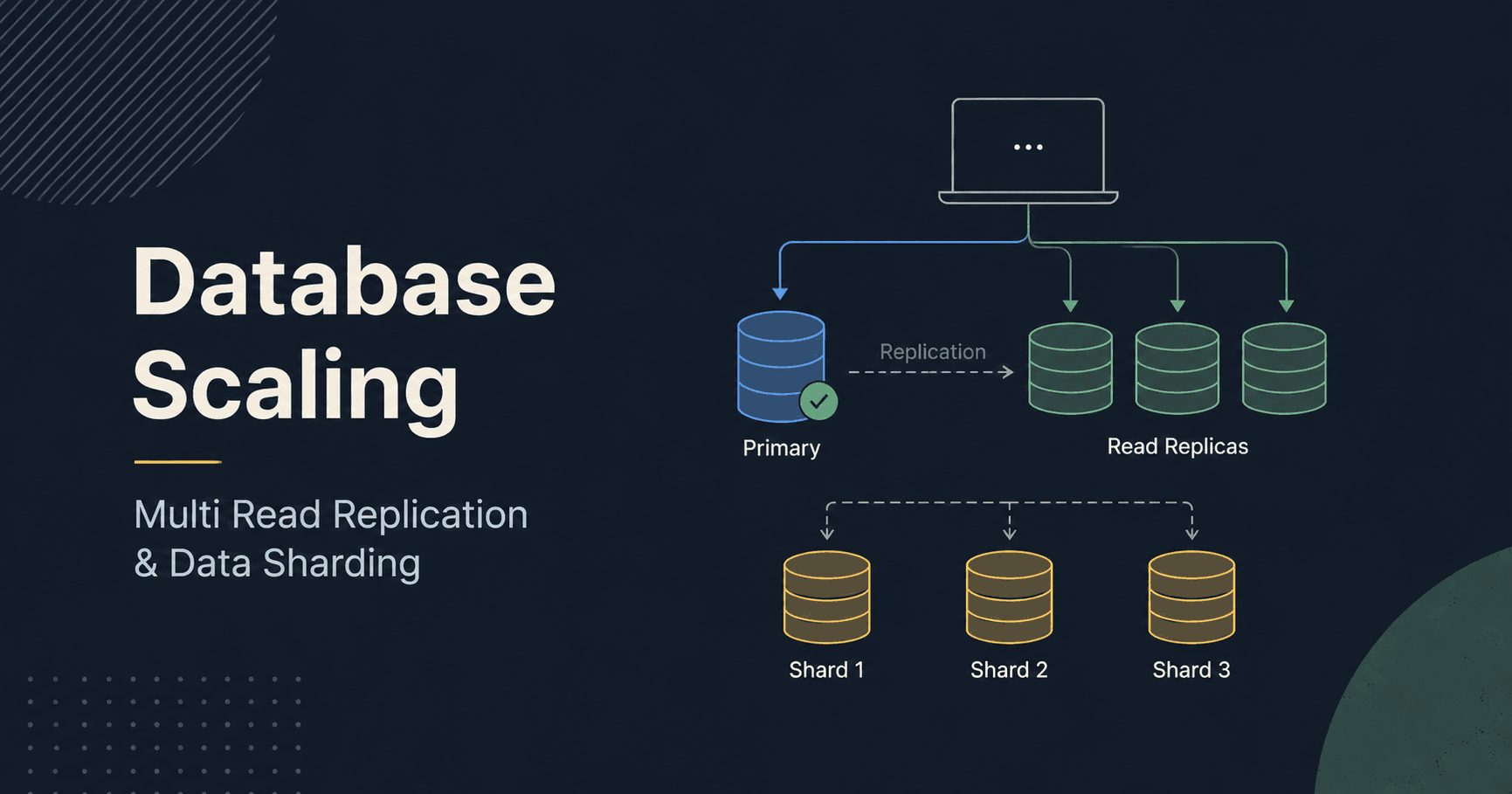
How Read Replication Works
We create:
Primary Database (Master)
Handles:
INSERT
UPDATE
DELETE
In short, all write operations.
Replica Databases (Read Replicas)
Handle:
SELECT queries
Data fetching
Reporting
The primary database continuously copies data to replicas.
Example:

Real-World Example
Imagine an e-commerce website.
When customers:
Browse products
View reviews
Search items
These requests go to read replicas.
When customers:
Place an order
Update address
Make payment
These requests go to the primary database.
This reduces load on the primary server significantly.
Benefits of Read Replication
Better Performance
Read traffic gets distributed across multiple servers.
Higher Availability
If one replica fails, another can serve requests.
Easy Scaling
Need more read capacity?
Simply add another replica.
Challenges of Read Replication
Replication Lag
Data doesn't always sync instantly.
Example:
User updates profile.
Update reaches Primary DB.
Replica updates 2 seconds later.
If the user immediately reads data from a replica, they may see old information.
This is called eventual consistency.
What is Data Sharding?
Read replication solves read-heavy workloads.
But what happens when:
Data becomes huge
Writes become too many
One database can no longer store everything
That's where sharding helps.
Understanding Sharding with an Example
Imagine a library with 100 million books.
Keeping all books in one room would be difficult.
Instead, the library splits books into multiple rooms.
For example:
Room A: A-H
Room B: I-P
Room C: Q-Z
Finding books becomes easier and faster.
Database sharding follows the same idea.
How Data Sharding Works
Instead of storing all data in one database:
Users Table
----------------
1
2
3
...
100 Million
We split data across multiple databases.
Example:

Shard 1
User IDs:
1 - 1,000,000
Shard 2
User IDs:
1,000,001 - 2,000,000
Shard 3
User IDs:
2,000,001 - 3,000,000
Each shard stores only a portion of the total data.
Common Sharding Strategies
1. Range-Based Sharding
Data is divided by ranges.
Example:
Users 1-1M -> Shard 1
Users 1M-2M -> Shard 2
Users 2M-3M -> Shard 3
Simple but may create uneven load.
2. Hash-Based Sharding
A hashing function determines where data goes.
Example:
UserID % 3
Results:
0 -> Shard 1
1 -> Shard 2
2 -> Shard 3
This usually distributes data more evenly.
3. Geographic Sharding
Data is split by region.
Example:
India Users -> India DB
Europe Users -> Europe DB
US Users -> US DB
Common in global applications.
Benefits of Sharding
Better Write Performance
Multiple databases share write traffic.
Massive Scalability
Store billions of records by adding more shards.
Lower Resource Usage
Each database manages a smaller dataset.
Faster Queries
Searching a smaller shard is often faster than searching one huge database.
Challenges of Sharding
Increased Complexity
Application logic becomes more complicated.
Cross-Shard Queries
Fetching data from multiple shards can be slow.
Rebalancing
When adding new shards, data may need to be redistributed.
Operational Overhead
More databases mean more monitoring and maintenance.
Read Replication vs Sharding
| Feature | Read Replication | Sharding |
|---|---|---|
| Solves Read Load | ✅ Yes | ⚠️ Partially |
| Solves Write Load | ❌ No | ✅ Yes |
| Increases Storage Capacity | ❌ No | ✅ Yes |
| Easy to Implement | ✅ Easier | ❌ Harder |
| Common Use Case | Read-heavy systems | Massive datasets and write-heavy systems |
Using Both Together
Large-scale systems often combine both approaches.
Example:
Load Balancer
|
----------------------
| |
Shard 1 Shard 2
| |
------------ ------------
| | | | | |
R1 R2 R3 R1 R2 R3
Where:
Data is split across shards.
Each shard has multiple read replicas.
Writes go to shard primaries.
Reads go to replicas.
This architecture is used by many large internet companies handling millions of users.
Final Thoughts
Database scaling is not just about handling more users—it's about maintaining a fast and reliable experience as your application grows.
A simple progression often looks like this:
Start with a single database.
Add read replicas when read traffic increases.
Introduce sharding when data size and write traffic become too large.
Combine both techniques for large-scale systems.
Understanding Read Replication and Data Sharding is an important step toward designing scalable systems that can support millions of users without sacrificing performance.